
Building a Data Engineering Stack That Boosts Scalability
Chart Mogul
NOVEMBER 30, 2023
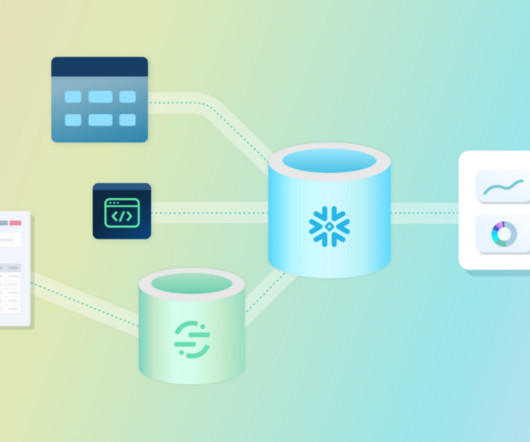
Updating the data engineering stack streamlined data processing; reducing the time and effort invested in manual data handling. Nowadays, these are packaged and deployed in docker images, and executed via AWS lambda or EKS pods each day. We used our daily AWS RDS snapshots and loaded them daily to Snowflake tables.




Let's personalize your content