
Building a Data Engineering Stack That Boosts Scalability
Chart Mogul
NOVEMBER 30, 2023
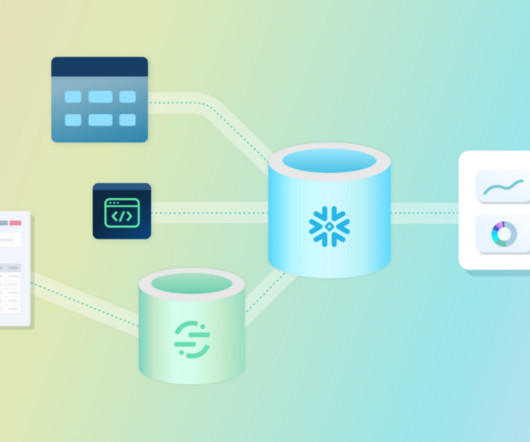
The aim was to ease data access across the company and allow data engineering functions to scale. We enabled logical replication AWS RDS instances, deployed Debezium and other Kafka connectors in our Kubernetes cluster which consume all real-time changes in Postgres tables, and stored them in relevant Kafka topics in our AWS MSK cluster.




Let's personalize your content